

This post was translated from Japanese and originally appeared on Qiita.
This is the day 10 post of the 2022 software test advent calendar blog series. I’m Yusuke Shibui, I work for Launchable as a Senior Software Engineer. I live in the machine learning space and I’ve written a few books that discusses the productization of ML systems. Take a look if you may:
This blog discusses Predictive Test Selection, which is a technique that applies ML to make test executions more efficient. If you are an engineer who struggles with test execution time/cost, read on.
Testing in today’s software development
It was 2002 when the book “Test Driven Development” came out, and since then writing tests in software development became the norm. Then, cloud and DevOps spread, thereby establishing the practice of running tests in CI/CD pipelines automatically to ensure code/product quality. There are all sorts of “tests” here: unit tests, integration tests, system tests, and so on. Many repositories and projects adopted the rule that says pull requests can be only merged if adequate test cases are written and if all the tests pass.

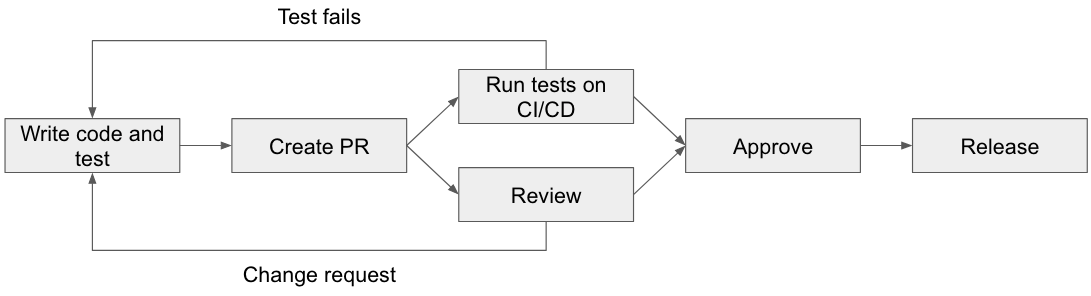
Nowadays, to add on top of this, it is common to see end-to-end tests, which touch all the layers of the software from end-user use case perspective. Among web services that include the UI/frontend pieces, e2e tests are table stakes, not just unit tests and integration tests. It’s simply a must-have to introduce e2e tests to test such a product, covering user screen transitions.
Historically, CI/CD has been run on engineer-managed environment like Jenkins. Today, hosted standalone CI services are available, such as GitHub Actions and CircleCI. So are cloud services like AWS Code Pipeline and Azure Pipelines. E2E test execution management services include mabl and autify. Writing code, including writing tests, is still dominated by local development computers, but increasingly test execution is shifting toward automation in free/paid cloud environments.
As your services expand and code grows, tests also increase their volume/type in lock step. Especially among long running services, test cases increase like dead code increases: tests that you have no idea when they got in, tests that you don’t know what they are testing. These problems have a detrimental effect on developer productivity for two reasons:
CI/CD turn around time & cost for unnecessary tests
People cost and the loss of motivation to maintain unnecessary-looking tests
As a result of running CI/CD on services, running tests costs money. Developers waiting for tests to finish adds to the time developers take to update/merge pull requests. Shorter cycle time leads to a rapidly improving valuable product getting in the hands of users. To shorten test execution time, we often resort to parallelization of tests or test execution environment improvements, but that translates to more spend on CI/CD services, including time cost. As the product and the software grows, test execution time and developer efficiency tends to go down (or the cost goes up).
The second “people cost & motivation” factor is even more problematic. I’m sure every newly written test had a valid reason, but as the software changes, some tests inevitably become unnecessary. However, figuring out if it became unnecessary requires the knowledge of product/software specs. AFAIK, most teams take a more conservative approach to deleting tests, compared to deleting code – you don’t know who wrote those tests, and you don’t want to be held accountable to the quality problem caused by that removal. As a result, people who maintain those unnecessary tests end up spending time on efforts that they do not feel are valuable.

My point is, writing tests and executing them in CI/CD aren’t enough to tame the challenges of maintaining the quality and improving developer productivity.
What is Predictive Test Selection?
If the 2000s brought test driven development, and 2010s brought CI/CD, then one of the new trends in 2020s is Predictive Test Selection (PTS). Meta (formerly Facebook) presented this test execution efficiency technique, where machine learning is used to select tests that matter for a given pull request.
The paper claims pass/fail of tests can be predicted by the code change and the past test execution records, to some extent. If you change code but not the relevant tests, that’ll likely increase the risk that those tests fail. If tests are failing often, regardless of the causes, the chance of this test failing next time is also likely high. Or if tests that are not modified for long time, and tests that have never failed, are unlikely to fail, setting aside for a moment whether those tests are valuable.
When code is small and tests are a few, one might be able to infer “if you change this code, that test might fail”, and/or “these tests are failing often, maybe it’ll fail again.” But as the software gets larger, that becomes impractical. Predictive Test Selection uses code change log and test execution history as an input, and applies machine learning to figure out which tests are more likely to fail for a given pull request.

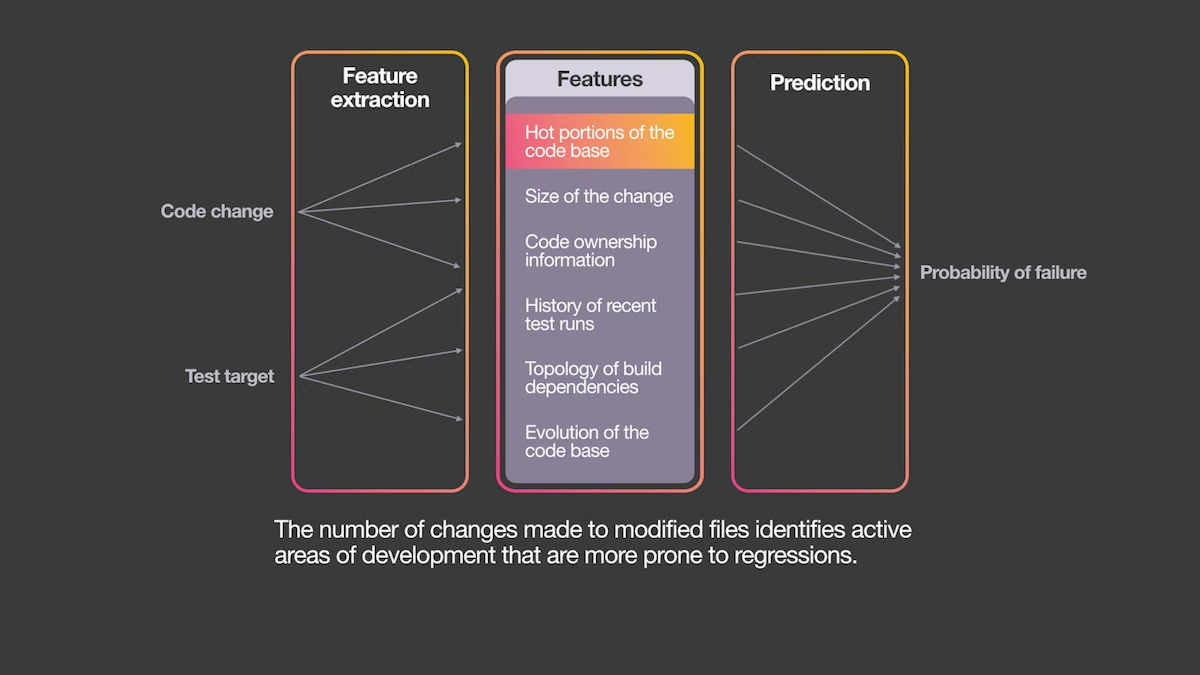
The paper uses the following features:
Change history for files
File cardinality
Target cardinality
Extensions of files
Number of distinct authors
Historical failure rate
Project name
Number of tests
Minimal distance between files and targets
Number of common tokens
The target data of the training is binary test pass/fail. The above features are fed into gradient boosting decision tree (GBDT). GBDT is an algorithm that combines gradient boost, model ensemble, and decision trees. The popular implementation includes XGBoost and LightGBM. It’s known to be a very effective technique to learn from tabular data. The paper states that they chose GBDT because the algorithm is readily available, trains quickly, performs well when positive & negative cases are not balanced, and can process ordinal/categorical data.
Test pass/fail data are recorded from CI/CD log per pull requests, along with code/test change data. Data for training gest accumulated automatically as CI/CD runs.

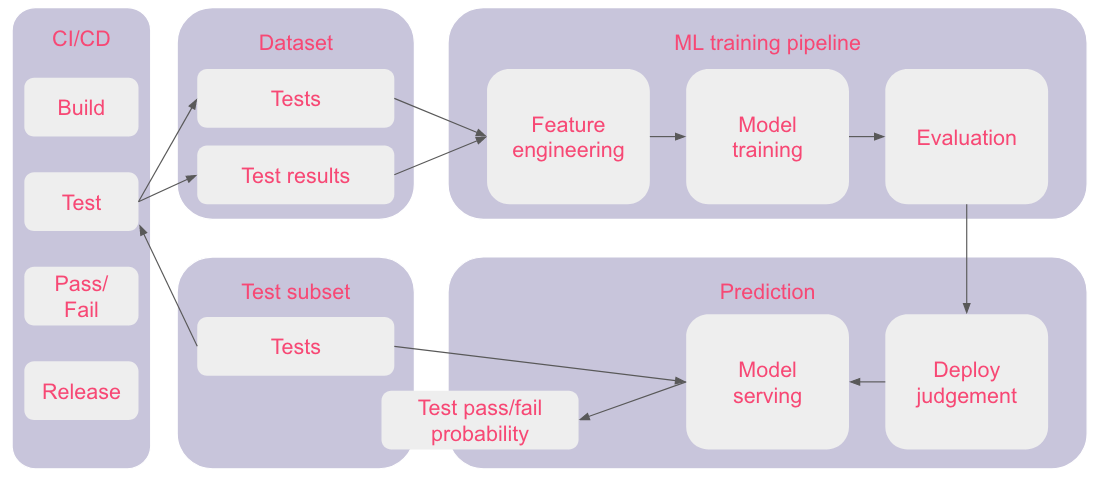
Once trained, a model is used to select tests to execute (= tests that are likely to fail). Test results are recorded for evaluation and as future training data.
The value of the model is to find tests that are likely to fail. Executing successful tests results in unnecessary test execution wait time and test resources. Conversely, missing tests that fail results in potential software quality problems. Predictive Test Selection packs the selected tests with tests that are likely to fail as much as possible. By choosing a subset of meaningful tests from all the tests, it reduces the wait time, lowers the cost, and improves the quality by running tests that fail. By making changes go through tests, it makes the test execution cycle more efficient in software development.

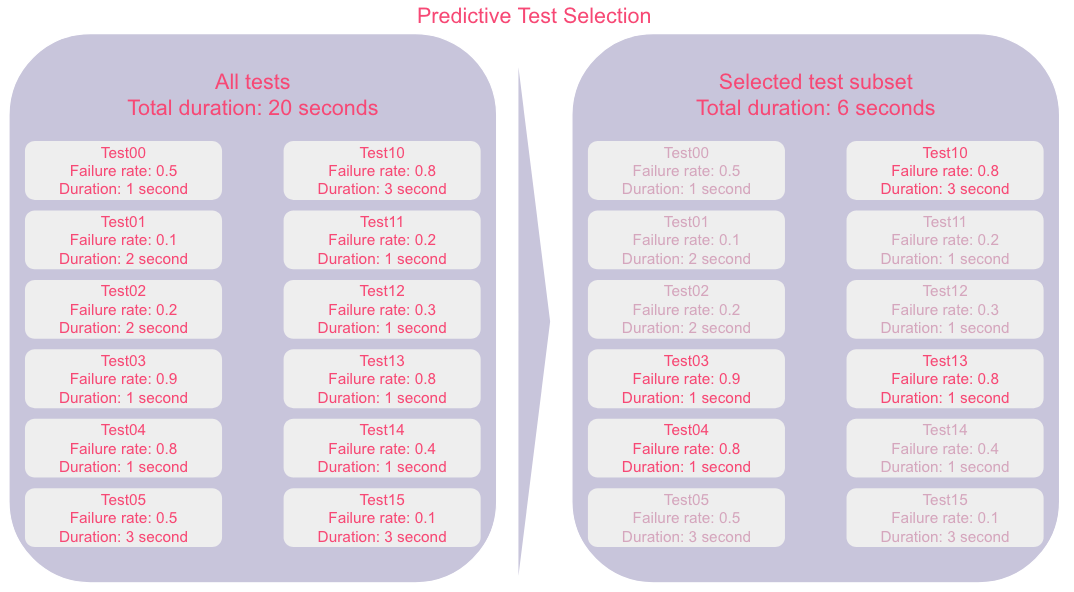
Tests are reordered in the likelihood of failures. This results in faster time to CI/CD failure, and shortens the time to start working on code fix. Imagine you have a test suite that takes 120 minutes to run. Let’s use Predictive Test Selection to select 60 minutes worth of tests that are more likely to fail. If you execute them randomly, on average engineers would wait for 30 minutes for a failure. Now if you execute tests in the order they are likely to fail, then the likelihood that this test suite will fail within the first 5 minutes get a lot higher. That means engineers can begin reworking the change after 5 minutes. In the age where CI/CD test execution is the norm and developers waiting for tests to come around is common place, I know you can see the value of CI/CD wait time going from 30 minutes to 5 minutes, regardless of your engineering org size.


Predictive Test Selection selecting tests to execute means tests that are not getting executed becomes clearer. Because it selects tests that are more likely to fail, based on code changes and test execution history, tests that are not getting selected consistently are tests that are unlikely to fail, or tests that are unrelated to code that are changed (or tests that are covering infrequently changing code). Put differently, these tests can be a prime target for removal, allowing test volume to come down (thus avoiding the maintenance overhead).
Test data analysis like Predictive Test Selection reveals another challenge – flaky tests. Flaky tests are randomly failing tests. When you modify unrelated code, or when you are not modifying code at all, if a test fails for some reason (such as external reasons or limited resources) then those tests are said to be flaky. Flakiness is difficult to remove, and often simple re-execution is enough to make them pass, so tackling flakiness tends to be de-prioritized.
What is a flaky test?
Flaky tests are tests cases that can pass and fail without changes to the code under test. By their nature, flaky tests reduce developer productivity and lead to a loss of confidence in testing.


Predictive Test Selection infers tests that are likely to fail because of the code change at hand. So it’s desirable not to have flaky tests among the selected tests. Because flakiness is random, by recording test execution results, one can calculate the level of flakiness of a test. Predictive Test Selection can exclude unrelated flaky tests from the subset, thereby eliminating the unnecessary test execution and triaging of failures.
(Note that it’s not good to ignore flaky tests; if you know the cause and it can be solved, it’s better to eliminate flakiness. In particular, flaky tests could be still failing for legitimate reasons, and if so, ignoring them could result in a software quality risk. See this paper for more about flakiness.)
Making test execution efficient not only helps maintain software quality, but also improves the software developer productivity. So there’s no wonder a practice like this emerged from Meta, who has a large software engineering team and provides planet-scale web service like Facebook, Instagram, Whatsapp, etc. Meta is not the only company who are doing this, too. Google published a paper “Taming Google-Scale Continuous Testing”.
Microsoft did “FastLane: Test Minimization for Rapidly Deployed Large-scale Online Services“, where they used ML to assess the risk (test failures) of a commit.
As the software gets larger and the engineering organization grows, automated test execution becomes a challenge that requires a creative solution. Though not Predictive Test Selection, Rakuten deployed a solution to make test execution more efficient (Japanese), too.
Test-driven development made writing tests table stakes; similarly, is running tests in CI/CD platforms such as Jenkins, GitHub Actions, and CircleCI. As the next step up from there, there’s a trend of making test execution efficient through techniques like Predictive Test Selection.